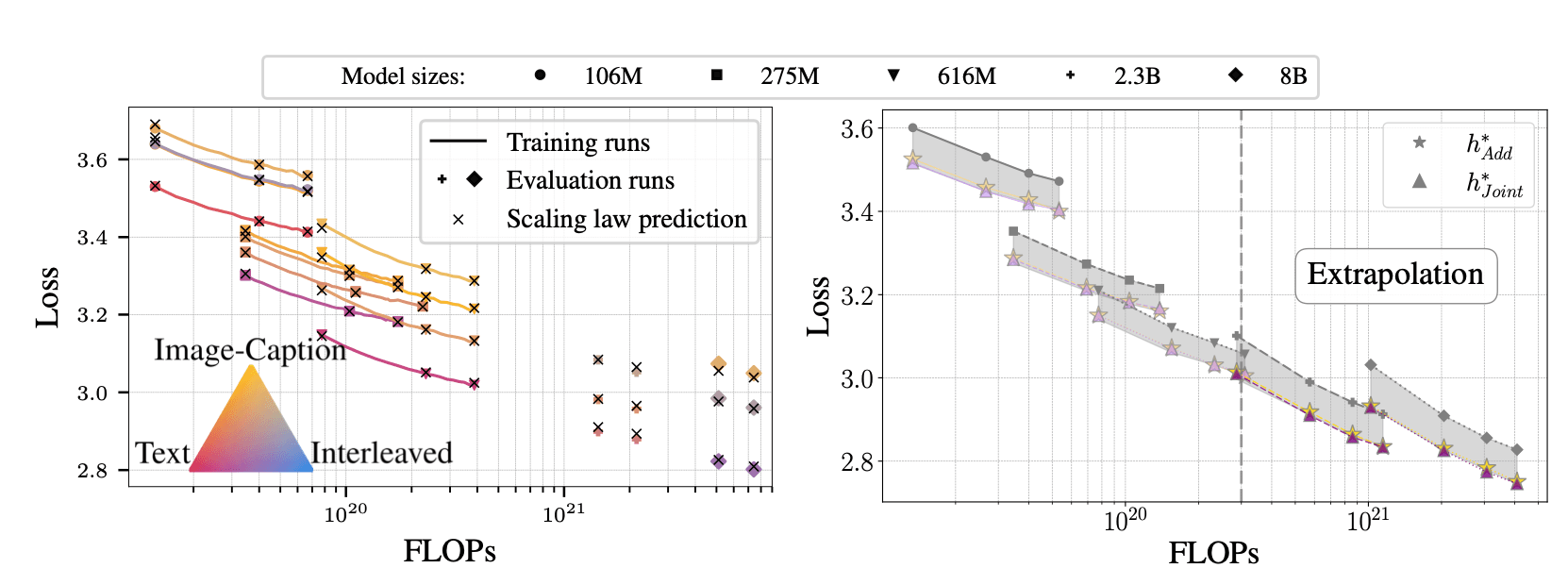
大型基础模型通常在来自多个域的数据上进行训练,数据混合——所用每个域的比例——在模型性能中起着至关重要的作用。选择这种混合物的标准方法依赖于试验和错误,这对于大规模的预训练来说变得不切实际。我们提出了一种系统方法,使用缩放规律确定任何目标域的最佳数据混合。我们的方法准确地预测了用D令牌和特定域权重向量h训练的N大小模型的损失。我们通过在三个不同的大规模环境中展示这些缩放规律的预测能力来验证其普遍性:大型语言模型(LLM)、原生多模态模型(NMM)和大型视觉模型(LVM)预训练。我们进一步表明,这些缩放定律可以推断到新的数据混合和跨尺度:它们的参数可以使用一些小规模的训练运行来准确估计,并用于估计更大规模和看不见的域权重的性能。缩放定律允许在给定的训练预算(N,D)下推导出任何目标域的最佳域权重,为昂贵的试错方法提供了原则性的替代方案。
Shukor, M., Bethune, L., Busbridge, D., Grangier, D., Fini, E., El-Nouby, A., & Ablin, P. (2025). Scaling laws for optimal data mixtures. arXiv. https://arxiv.org/abs/2507.09404